

As your data volume and query load grow, you scale SurrealDB Cloud to avoid throttling, high latency, or storage exhaustion. How you scale depends on your plan: Start instances grow vertically on one node, while Scale clusters grow horizontally on SurrealDS.
Choosing Start vs Scale
| Aspect | Start | Scale |
|---|---|---|
| Growth model | Larger instance type on one node | More compute units (query nodes) |
| Fault tolerance | Single point of failure within the instance | Multi-node cluster; survives loss of one node |
| Operational model | Single-node managed option | Managed cluster — no self-hosted Kubernetes or replication stack |
| Typical fit | Dev, staging, cost-sensitive production | Business-critical production, horizontal throughput |
Move to Scale when a single node is no longer enough — because you need fault tolerance, sustained query throughput across nodes, or both — not only because disk is full. Scale runs a minimum of three compute units; see High availability for why that matters.
Vertical scaling (Start)
Vertical scaling means moving to a larger instance type with more CPU, memory, storage, or I/O on a single node. It is the default approach on the Start plan when metrics show sustained high utilisation on one instance.
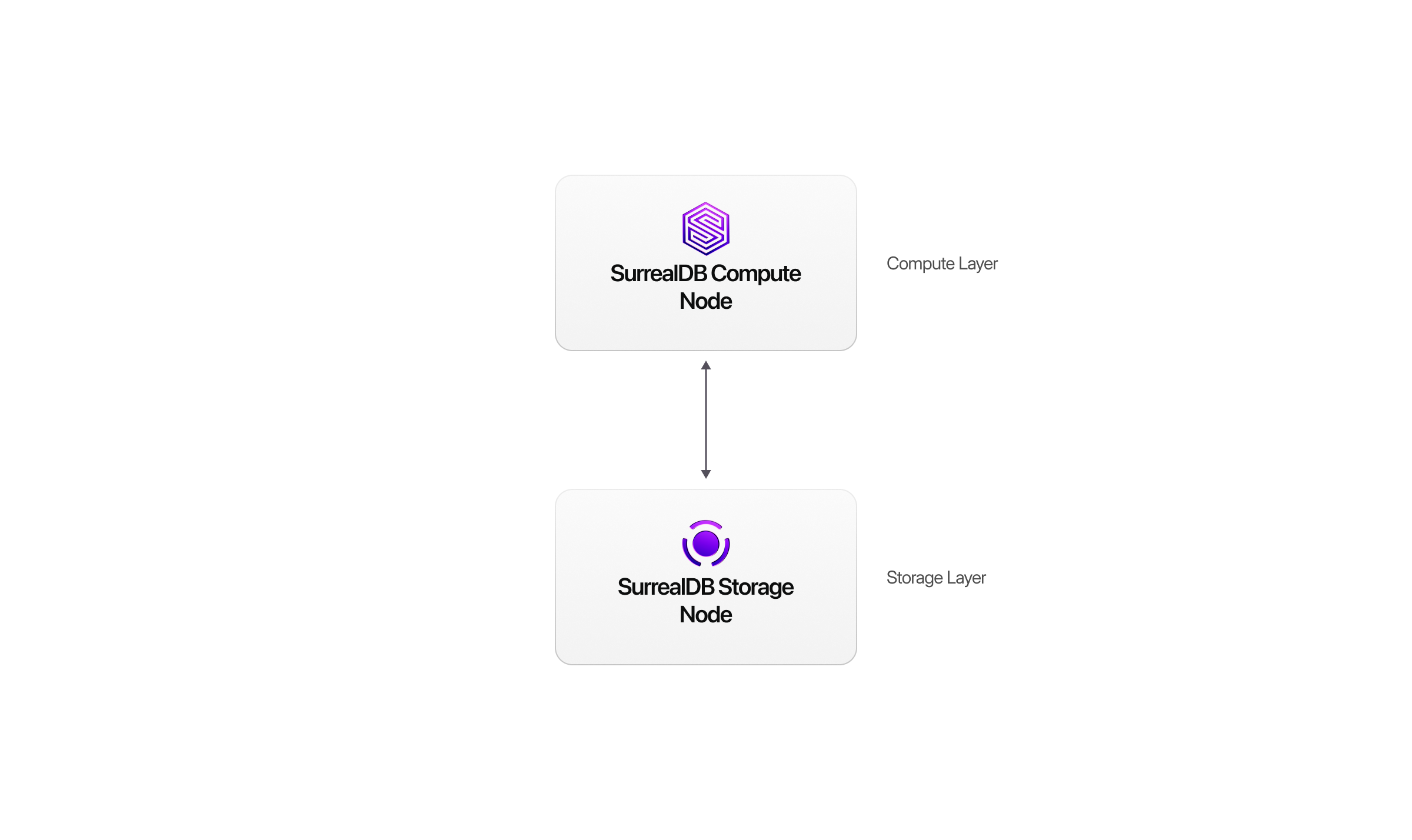
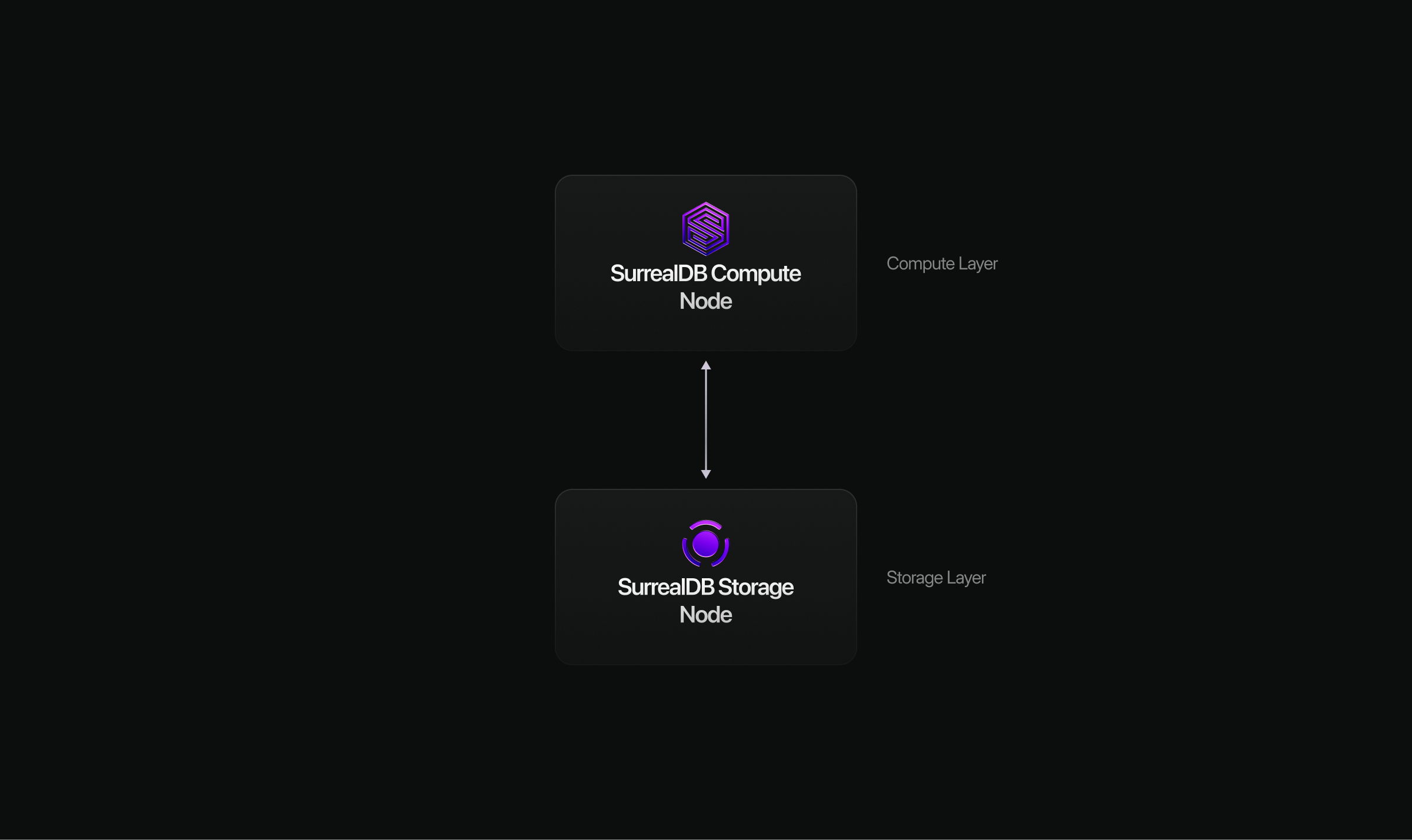
Horizontal scaling (Scale)
Horizontal scaling on the Scale plan adds compute nodes to a multi-node cluster backed by SurrealDS. The storage tier handles replication, consensus, and distributed transactions. Use Scale when you need to survive node failure, spread query load, or prefer to avoid operating a self-hosted distributed cluster.
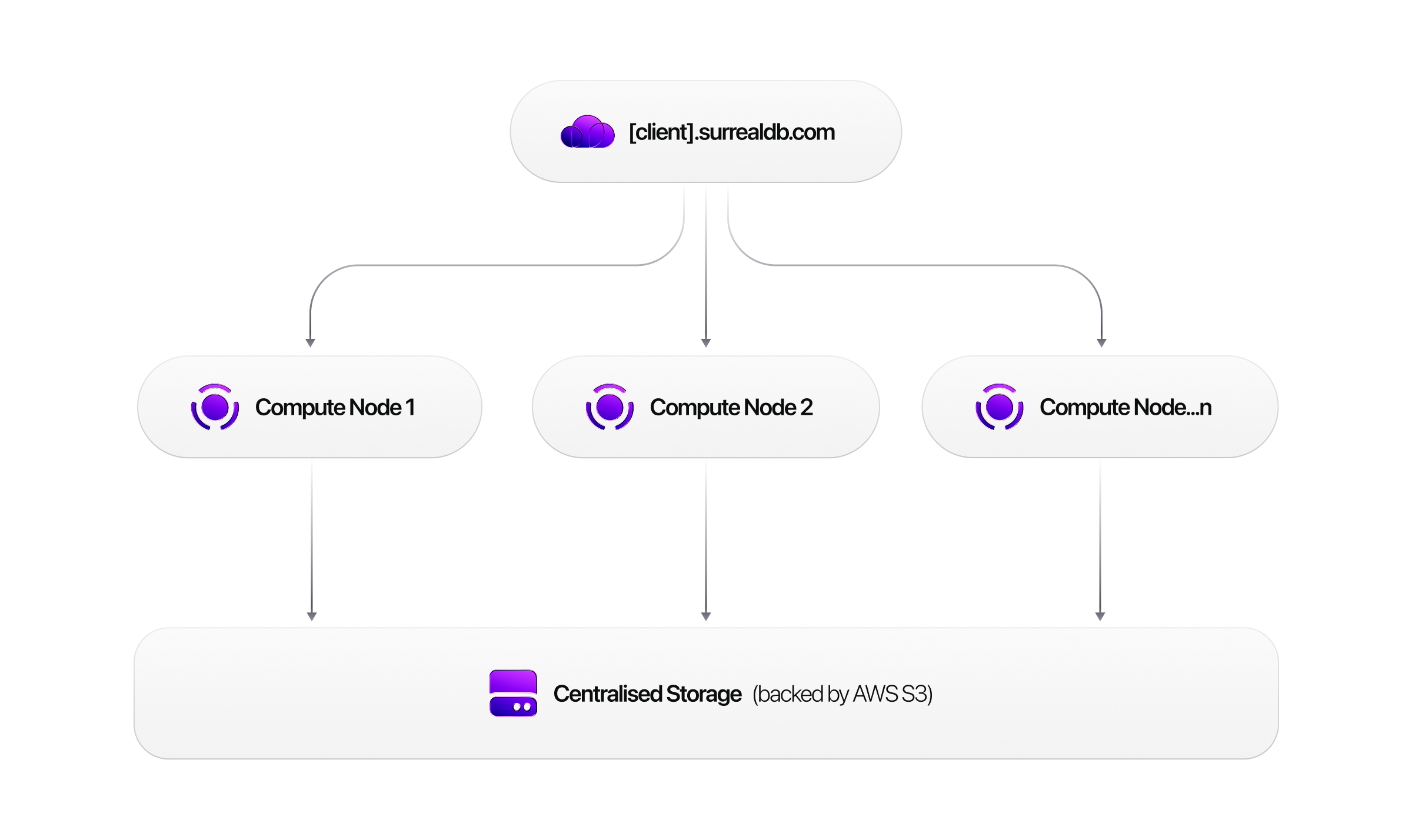
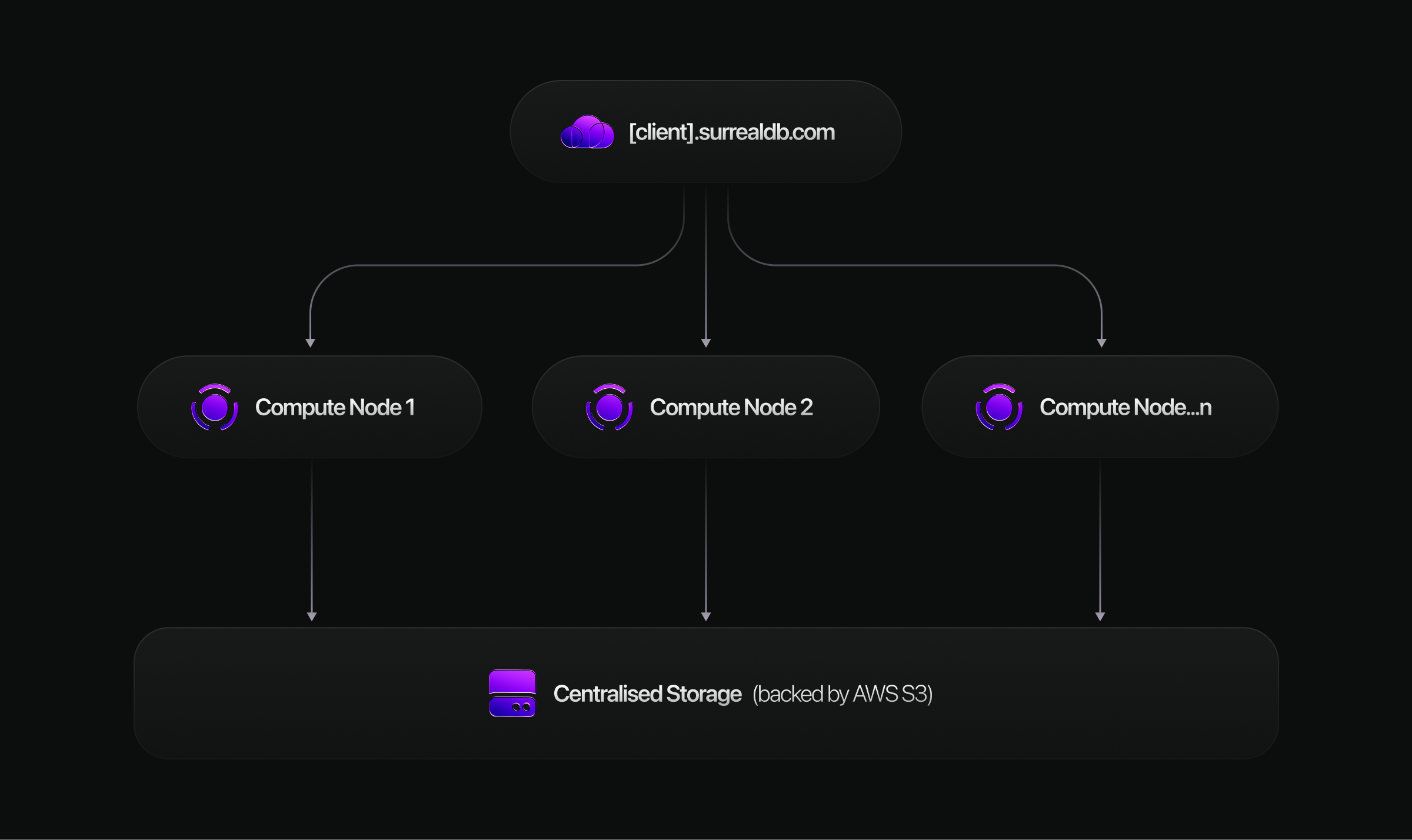
See Cloud architecture for how Start and Scale differ.
When to scale
Signals to scale include CPU pegged near limits, memory pressure, disk growth trending toward limits, connection saturation, and latency SLOs breached under normal traffic. Schedule resizes during maintenance windows when possible; some changes may cause brief reconnects.
On Scale, also watch per-node balance and storage growth on the cluster — horizontal scale may require both more compute units and additional storage.
How to resize
Change the instance type, compute units, or storage from the Cloud console or Surrealist, following any confirmation steps for your plan. After scaling, re-check metrics and query performance to validate the new size.
For operational scaling detail in the deployment guide, see Scaling operations.